
Eric Mann, Director of Product Engineering at Kochava, authors, “The Code We Live By,” a new blog series that gives us a behind-the-scenes look at what makes a real-time measurement data provider work smoothly.
This first post introduces us to the complex world of recording data globally in the most efficient manner. Mann and his team have designed a fault-tolerant system that constantly improves itself. As you can imagine, building an international data system is no small feat. It is the challenge of solving a million-piece jigsaw puzzle with multiple players within fractions of a second. Welcome to the world of Kochava developers.
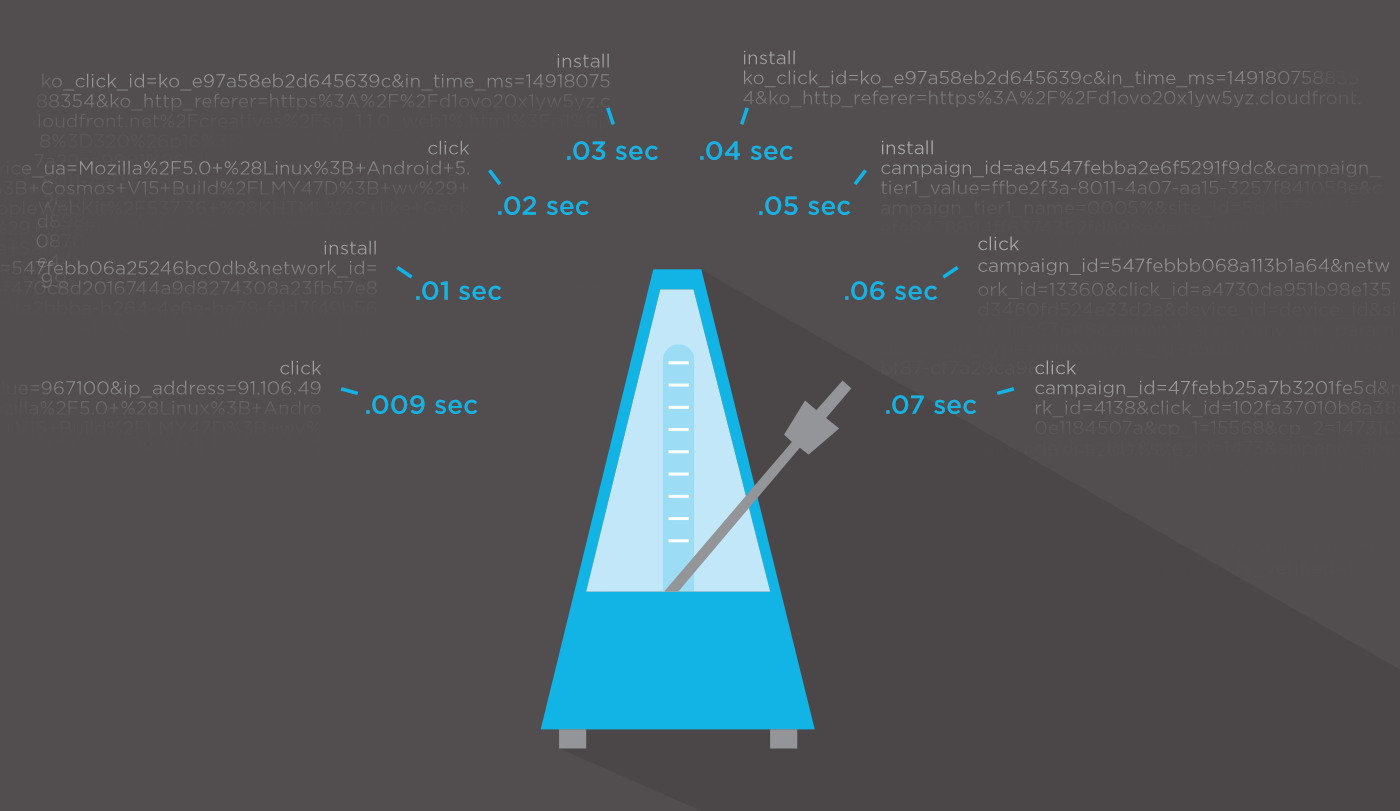
There are certain challenges when building real-time systems that require detailed coordination and infrastructure definition when compared to other services in ad tech. In our world, we’re bound by a requirement of FIFO at the millisecond level. I liken this to putting together a million-piece puzzle with 100 colleagues where each colleague is required to attach the next piece while keeping in time with a metronome ticking every millisecond. Everyone still with me? Let’s continue!
Often the question of application architecture, even service architecture, starts with the definition of “real time.” I’ve heard tales of companies willing to throw cloud-based solutions off the table claiming that self-hosting hardware gives the advantage of resiliency at a lower cost. Or, alternatively, throw self-hosted solutions off the table and hand over their system under a single provider.
We’ve architected Kochava with the best of both worlds, allowing for this time-correct puzzle, that we call real-time attribution, to be assembled correctly, in the right order, with infrastructure spread across the globe with cloud-based providers, and co-located in data center hubs on our own hardware. Let’s unpack some advantages and considerations of building a high-volume system with this hybrid approach.
Data ingestion on a global scale
“The cloud” has become a buzzword for either the solution to or cause of (depending on your perspective) many issues with scaling tech infrastructure. However, it’s important to remember that ”the cloud” is just somebody else’s computer. Don’t be tricked into thinking that either a) cloud computing is better or, b) on-premise computing is more flexible. Both can be true, both can be false. It’s kind of like the choice between renting or buying a home. If you buy, you are the master of your destiny, but you’re also responsible for all maintenance and upkeep costs. If you rent, the infrastructure is someone else’s problem, but you probably can’t knock down the wall between the kitchen and living room. Make sure you’re not creating a false dichotomy when considering different architectural approaches.
Using a cloud provider with a private backhaul, such as Google, allows us to house clusters of ingestion systems, all automatically deployed, in different regions of the globe—all sitting on privately owned (and pretty quick) Google fiber. For example, under normal load, we float around 65 ingestion point instances, regionally distributed, primarily via the Google’s Compute Engine.
Why is this important?
- Lower SDK network footprint
- Snappy click redirects
- Reduced latency for our partners
- Global network redundancy
Picture, for instance, that we decided to use a single datacenter (or region) as our ingestion center for global traffic. I’ve taken an average sample of the latency profile (how long a system takes) for click redirects and/or SDK communication in this scenario, which I’ve setup in Frankfurt.
[64 bytes from 178.162.216.219: ttl=40 time=283.805 ms]
Let’s run the same test but instead resolve the Kochava ingestion system.
[64 bytes from 107.178.254.148: ttl=54 time=16.572 ms]
A time range from 16 ms to 283 ms is a latency improvement of 17x. This is made possible because our endpoint auto-resolves to the lowest latency ingestion point. In this scenario, it resolved to one of our ingestion points in Oregon. At scale, this creates a measurable impact. Not only for user experiences like click redirection but also reducing our SDK’s network footprint and external partner communication latency. For our customers using our S2S offerings, having an endpoint respond 17x faster also saves significant infrastructure as applications are able to complete a request to Kochava and move on to their next task.
This model of geographic load balancing becomes even more advantageous to Kochava customers when there is a large-scale internet disruption in a certain region or with certain backhaul providers. Our load balancers automatically reroute traffic to compute instances in normalized traffic instances, allowing an uninterrupted traffic flow and a maintained level of latency. Interrupted response thresholds have impacts beyond simply click redirects. More network latency means potential SDK interruption and external partner impact. We’ve packaged internal queues and retry logic into our SDKs for scenarios when disruption is unavoidable. Minimizing the opportunity for traffic interruptions is critical to maintaining top north syndication to partner systems and real- time decisions in ad buys.
Variable traffic throttling
A challenge of any distributed computing system is how each instance should react when there are interruptions in peered systems across multiple datacenters. We’ve designed our ingestion system to be aware of network connectivity issues that may be sending larger swaths of traffic to certain regions. and to update traffic processing to maintain our processing order cross-region.
Each of our ingestion points communicates with all peer instances via an encrypted representation of their entire processing state ten times per second. This state includes things such as how large is each traffic queue, a representation of time-sorted traffic, network latency, incoming traffic volumes, and over 100 additional data points that keep these systems in sync across the globe. The result is that at any time, each ingestion point knows how to behave in relation to all other ingestion peers.
With 65 ingestion points representing over 100 states every 100 milliseconds, our incoming traffic queue profile is evaluated globally over 65,000 times per second for FIFO consistency. The result? We clear each second of traffic before moving on to the next, across the globe. These ingestion systems unfold the traffic into our core processing systems for a true FIFO result and help to have strong data consistency.
Commodity hardware and systems: Processing billions of records
Over the past two years, we’ve moved away from languages such as Node.js and PHP (and a few others) to Go. Go has allowed our team to create a rich repository of lightning-fast applications and packages for quick and agile development of new services. What used to take 100+ cores to run, we can now optimize down to running on the equivalent of a couple of Raspberry Pis.
Take our Global Fraud Blocklist, a new system at Kochava that processes billions of real-time transactions and validates them against our library of known fraud metrics and blocklists. During a normalized traffic load, this system runs on just a fraction of the cores it would have previously required and scales up to 100x capacity at a moment’s notice.
These types of optimizations allow us to set up commodity clusters of machines to run dockerized instances of our application stack—either behind a dynamic proxy or as a consumer service—any of which scale with the traffic load. Our applications run with a command as simple as “docker run traffic-verification” and scale with a simple POST request, or click to our clustering service.
The majority of our data processing (once external ingestion has been completed by our ingestion cloud) is done in a co-located data center. These clusters are an extremely cost-effective way to process cloud-scale transactions on owned hardware. Our move to containerization and a “run local” model means we can move these services to any machine, cloud or owned, at a moment’s notice or in failover scenarios.
We believe strongly that continuously improving our system is critical to maintaining our technological advantage over others in the space. It ensures that our customers are interacting with state-of-the-art tech—data that’s valid and consistent against an ever-changing industry—and systems that don’t buckle under pressure, even as new marketers move to mobile at a global scale.
See why we're the bestAbout the Author
 Eric Mann is the Director of Product Engineering at Kochava where he spends his days both hands-on with the codebase, as well as alongside fellow developers to architect, build, and sustain Kochava products and services. In addition to his role inside of Product/Development, Eric enjoys working directly with clients on implementations of the Kochava platform.
Eric Mann is the Director of Product Engineering at Kochava where he spends his days both hands-on with the codebase, as well as alongside fellow developers to architect, build, and sustain Kochava products and services. In addition to his role inside of Product/Development, Eric enjoys working directly with clients on implementations of the Kochava platform.


